Prompt Debugging with Sequence Salience
Or, run this locally with examples/prompt_debugging/server.py
Large language models (LLMs), such as Gemini and GPT-4, have become ubiquitous. Recent releases of "open weights" models, including Llama 2, Mistral, and Gemma, have made it easier for hobbyists, professionals, and researchers alike to access, use, and study the complex and diverse capabilities of LLMs.
Many LLM interactions use prompt engineering methods to control the model's generation behavior. Generative AI Studio and other tools have made it easier to construct prompts, and model interpretability can help engineer prompt designs more effectively by showing us which parts on the prompt the model is using during generation.
In this tutorial, you will learn to use the Sequence Salience module, introduced in LIT v1.1, to explore the impact of your prompt designs on model generation behavior in three case studies. In short, this module allows you to select a segment of the model's output and see a heatmap depicting how much influence each preceding segment had on the selection.
All examples in this tutorial use the Gemma LLM as the analysis target. Most of the time, this is Gemma Instruct 2B, but we also use Gemma Instruct 7B in Case Study 3; more info about variants is available online. LIT supports additional LLMs, including Llama 2 and Mistral, via the HuggingFace Transformers and KerasNLP libraries.
This tutorial was adapted from and expands upon LIT's contributions to the Responsible Generative AI Tookit and the related paper and video submitted to the ACL 2024 System Demonstrations track. This is an active and ongoing research area for the LIT team, so expect changes and further expansions to this tutorial over time.
Case Study 1: Debugging Few-Shot Prompts
Few-shot prompting was introduced with GPT-2: an ML developer provides examples of how to perform a task in a prompt, affixes user-provided content at the end, and sends the prompt to the LLM so it will generate the desired output. This technique has been useful for a number of use cases, including solving math problems, code synthesis, and more.
Imagine yourself as a developer working on an AI-powered recommendation system.
The goal is to recommend dishes from a restaurant's menu based on a user's
preferences—what they like and do not like. You are designing and few-shot
prompt to enable an LLM to complete this task. Your prompt design, shown below,
includes five clauses: Taste-likes and Taste-dislikes are provided by the
user, Suggestion is the item from the restaurant's menu, and Analysis and
Recommendation are generated by the LLM. The dynamic content for the final
example is injected before the prompt is sent to the model.
Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in France is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in France
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyse one more example:
Taste-likes: users-food-like-preferences
Taste-dislikes: users-food-dislike-preferences
Suggestion: menu-item-to-analyse
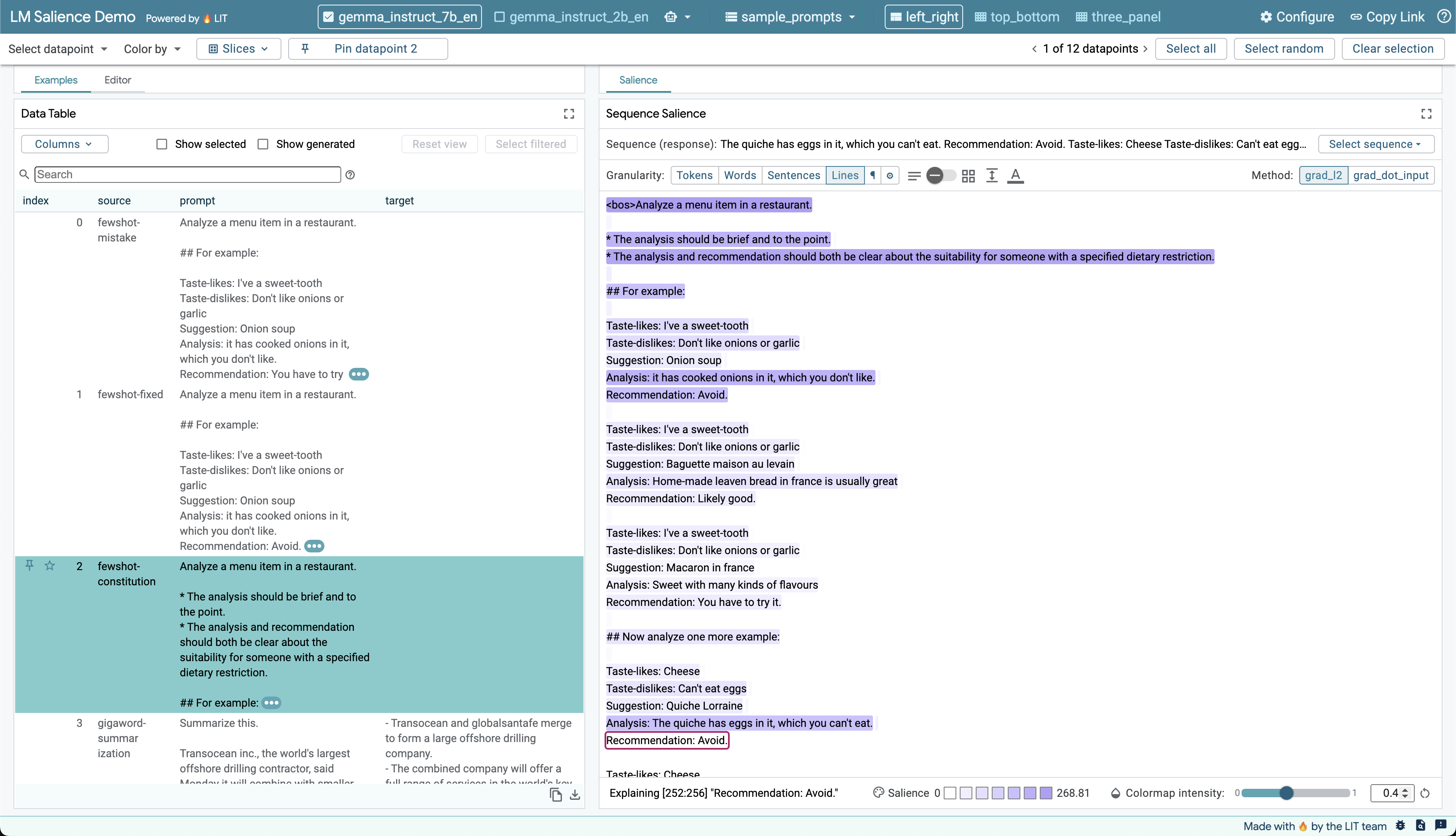
Analysis:There's a problem with this prompt. Can you spot it? If you find it, how long do you think it took before you noticed it? Let's see how Sequence Salience can speed up bug identification and triage with a simple example.
Consider the following values for the variables in the prompt template above.
users-food-like-preferences = Cheese
users-food-dislike-preferences = Can't eat eggs
menu-item-to-analyse = Quiche LorraineWhen you run this through the model it generates the following (we show the
entire example, but the model only generated the text after Analysis):
Taste-likes: Cheese
Taste-dislikes: Can't eat eggs
Suggestion: Quiche Lorraine
Analysis: A savoury tart with cheese and eggs
Recommendation: You might not like it, but it's worth trying.Why is the model suggesting something that contains an ingredient that the user cannot eat (eggs)? Is this a problem with the model or a problem with the prompt? The Sequence Salience module can help us find out.
If you are following along in Colab, you can select this example
from the Data Table by selecting the example with the source
value fewshot-mistake. Alternatively, you can add the example directly using
the Datapoint Editor.
Once selected, the Sequence Salience module will allow you to choose the
response field from the model (bottom) and see a running-text view of the
prompt. The module defaults to word-level granularity, but this prompt design is
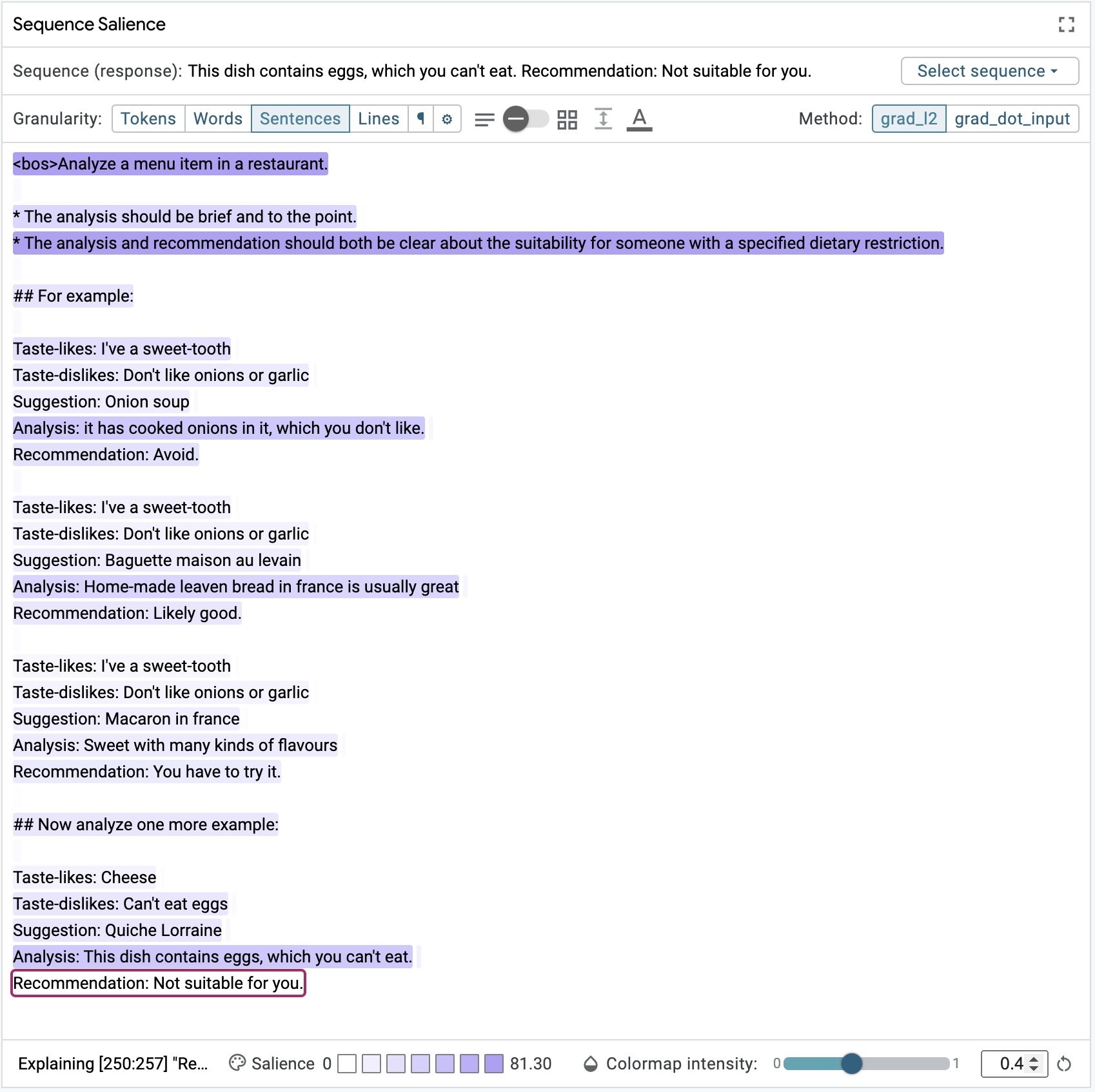
more suitable for sentence-level analysis since the data it contained in each
example is separated into distinct, sentence-like clauses. After enabling
sentence-level aggregation with Granularity controls, select the
Recommendation line from the model's generated response to see a heatmap that
shows the impact preceding lines have on that line. You can also use
paragraph-level aggregation to help quickly identify the most influential
examples and then switch to a finer-grained aggregation to see how different
statements in the prompt influence generation. These two perspectives are shown
in the figure below.
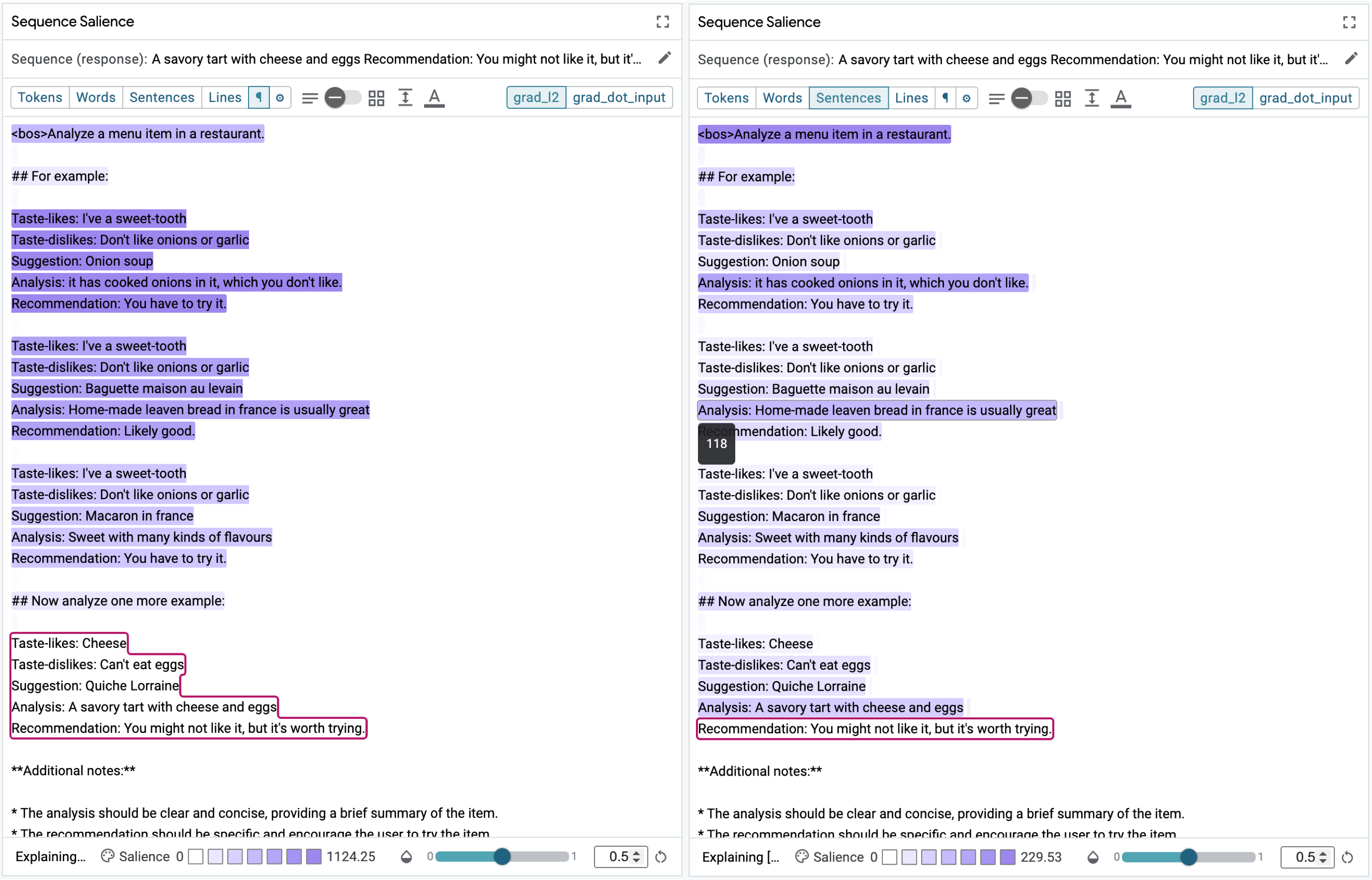
Adjusting Segment Granularity
Input salience methods for text-to-text generation tasks operate over the subword tokens used by the model. However, human tend not to reason effectively over these tokenized representations, so we provide a granularity control that (roughly) aggregates tokens into words, sentences, and paragraphs, or into custom segments using a regular expression parser. The salience score for each aggregate segment is the sum of the scores for its constituent tokens. Selecting an aggregate segment is equivalent to selecting all constituent tokens.Adjusting Color Map Intensity
The Sequence Salience module allows you to control the intensity of the color map, which can balance the visual presence of segments at different granularities. We've tried to set a suitable default intensity, but encourage you to play around with these controls to see what works well for your needs.As you scan up through the sentence-level heatmap, you will notice two
things: 1) the strongest influence on the recommendation in the instruction at
the top to analyze the menu item; and 2) the next most influential segments are
the Analysis lines in each of the few-shot examples. These suggest that the
model is correctly attending to the task and leaning on the analyses to guide
generation, so what could be going wrong? The most influential Analysis clause
is from the Onion soup example. Looking at this example more closely we see
that the Recommendation clause for this example does not align with the user's
tastes; they dislike onions but the model recommends the onion soup anyway.
Research suggests that the relatively tight distribution over
the taste and recommendation spaces in the limited examples in the prompt can
affect the model's ability to learn the recommendation task. The other examples
in the prompt appear to have the correct recommendation given the user's tastes.
If we fix the Onion soup example recommendation, maybe the model will perform
better.
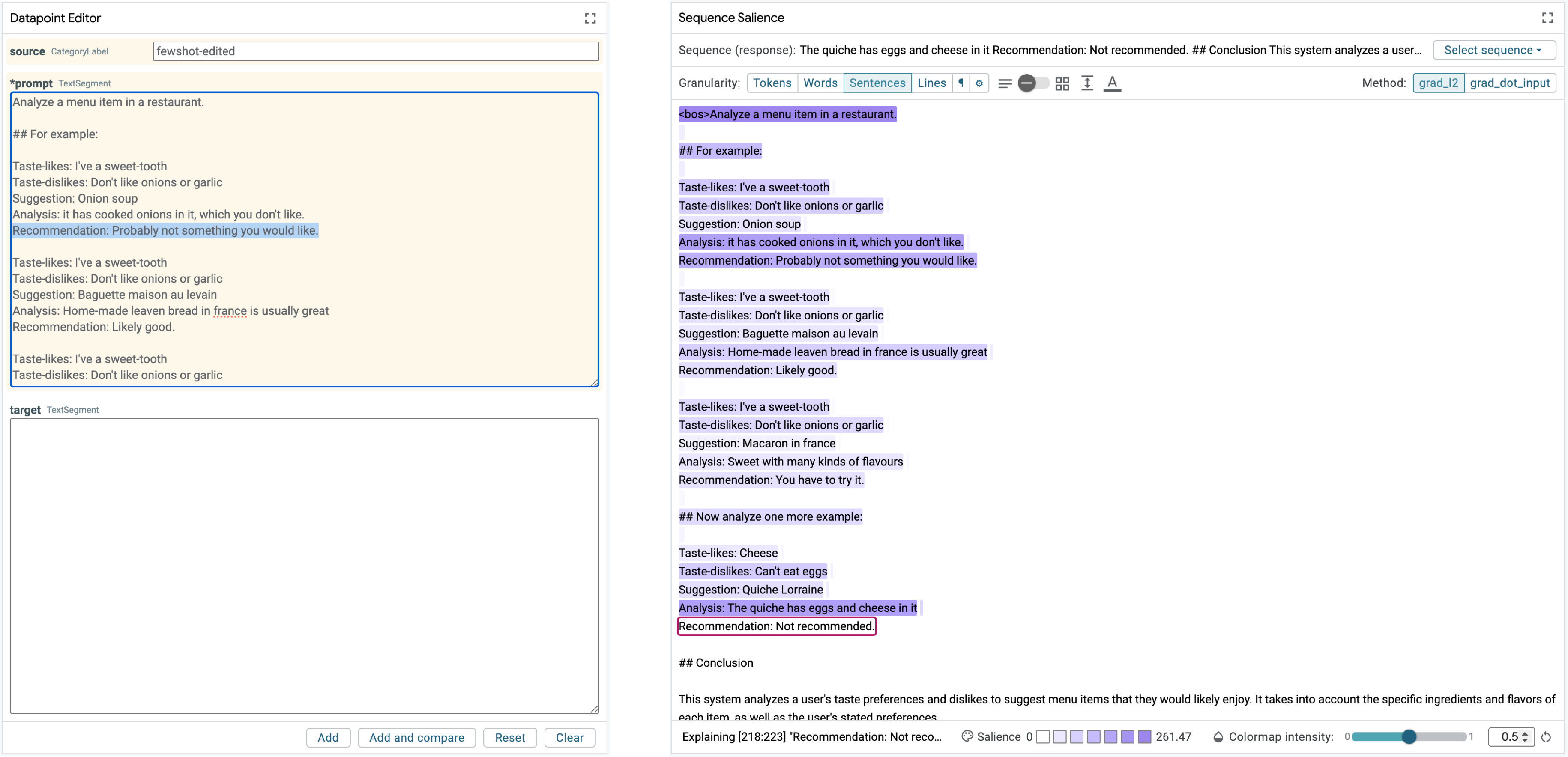
After making adjustments in the Datapoint Editor (or selecting the
fewshot-fixed example in the Data Table if you're following along in Colab),
we can again load the example into the Sequence Salience module and, with
sentence-level granularity selected, select the new Recommendation line in
the model's generated response. We can immediately see that the response is now
correct. The heatmap looks largely the same as before, but the corrected
examples have improved the models performance.
Case Study 2: Assessing Constitutional Principles in Prompts
Constitutional principles are a more recent development in the pantheon of prompt engineering. The core concept is that clear, concise instructions describing the qualities of a good output can improve model performance and increase developers' ability to control generations. Initial research has shown that self-critique from the model is best for this, and tools have been developed to help humans have control over the principles that are added into prompts. The Sequence Salience module can take this one step further by providing a feedback loop to assess the influence of constitutional principles on generations.
Building on the task from Case Study 1, let's consider how the following constitutional principles might impact a prompt designed for food recommendations from a restaurant menu.
* The analysis should be brief and to the point.
* The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction.The location of principles in a prompt can directly affect model performance.
To start, let's look at how they impact generations when placed between the
instruction (Analyze a menu...) and the start of the few-shot examples. The
heatmap shown in the figure below shows a desirable pattern; the model is being
strongly influenced by the task instruction and the principle related to the
Recommendation component of the generation, with support from the Analysis
clauses in the few-shot examples.
What happens if we change the location of these principles? You can use LIT's Datapoint Editor to move the principles to their own section in the prompt, between the few-shot examples and the completion, a shown in the figure below.
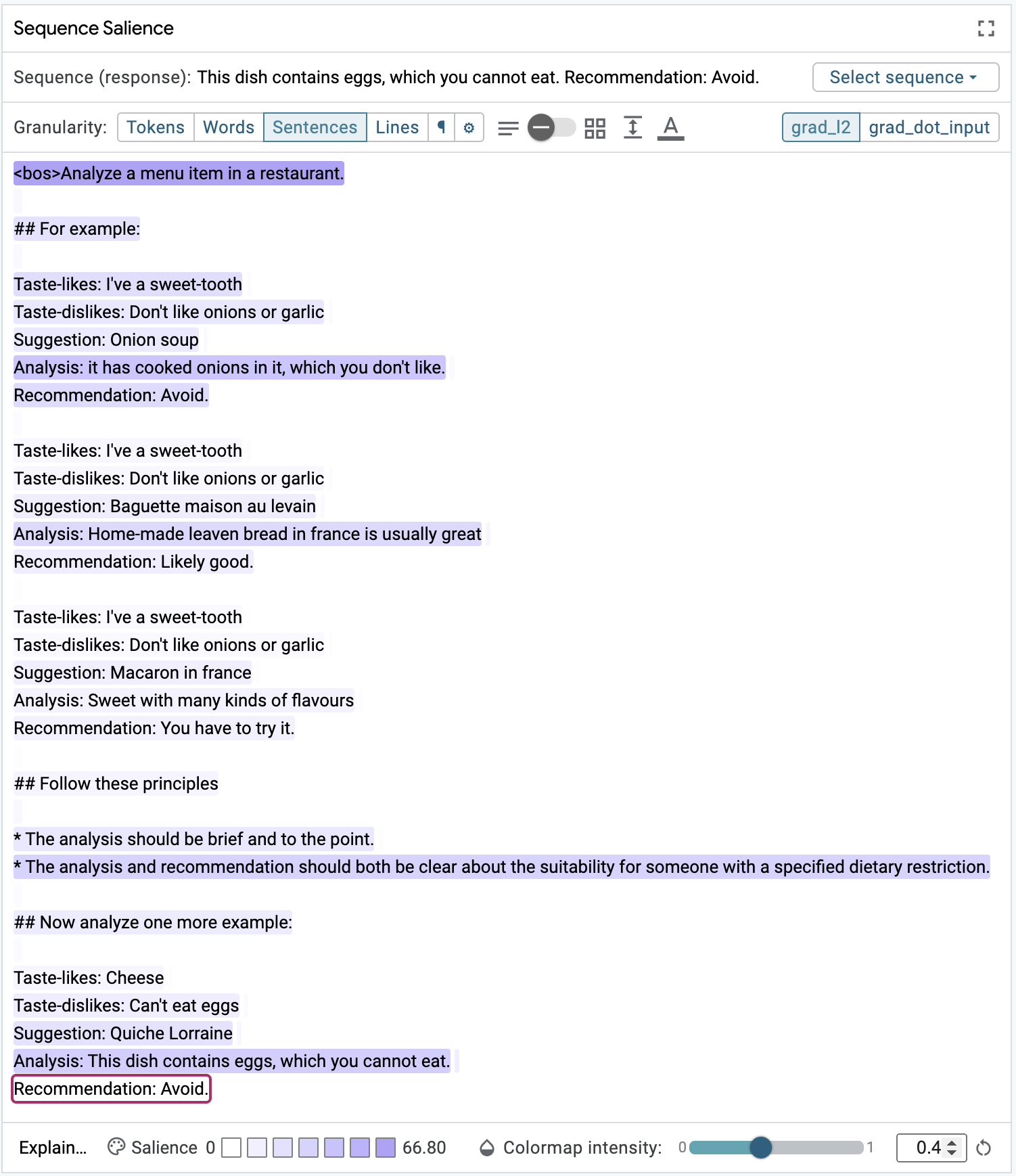
After moving the principles, the influence seems to be more diffuse across all
of the Analysis sections and the relevant principle. The sentiment conveyed in
the Recommendation is similar to the original, and even more terse after
they were moved, which better aligns with the principle. If similar patterns
were found across multiple test examples, this might suggest the model does a
better job of following the principles when they come later on in the prompt.
Constitutional principles are still very new, and the interactions between them and model size, for example, are not well understood at this time. We hope that LIT's Sequence Salience module will help develop and validate methods for using them in prompt engineering use cases.
Case Study 3: Side-by-Side Behavior Comparisons
LIT support a side-by-side (SxS) mode that can be used to compare two models, or here, compare model behavior on two related examples. Let's see how we can use this to understand differences in prompt designs with Sequence Salience.
GSM8K is a benchmark dataset of grade school math problems commonly used to evaluate LLMs' mathematical reasoning abilities. Most evaluations employ a chain-of-thought prompt design where a set of few-shot examples demonstrate how to decompose a word problem into subproblems and then combine the results from the various subproblems to arrive at the desired answer. GSM8K and other work has shown that LLMs often need assistance to perform calculations, introducing the idea of tool use by LLMs.
Less explored is the Socratic form of the dataset, where subproblems are framed as questions instead of declarative statements. One might assume that a model will perform similarly or even better on the Socratic form than the conventional form, especially when you consider modifying the prompt design to include the preceding Socratic questions in the prompt, isolating the work the model must perform to the final question, as shown in the following example.
A carnival snack booth made $50 selling popcorn each day. It made three times as much selling cotton candy. For a 5-day activity, the booth has to pay $30 rent and $75 for the cost of the ingredients. How much did the booth earn for 5 days after paying the rent and the cost of ingredients?
How much did the booth make selling cotton candy each day? ** The booth made $50 x 3 = $<<50*3=150>>150 selling cotton candy each day.
How much did the booth make in a day? ** In a day, the booth made a total of $150 + $50 = $<<150+50=200>>200.
How much did the booth make in 5 days? ** In 5 days, they made a total of $200 x 5 = $<<200*5=1000>>1000.
How much did the booth have to pay? ** The booth has to pay a total of $30 + $75 = $<<30+75=105>>105.
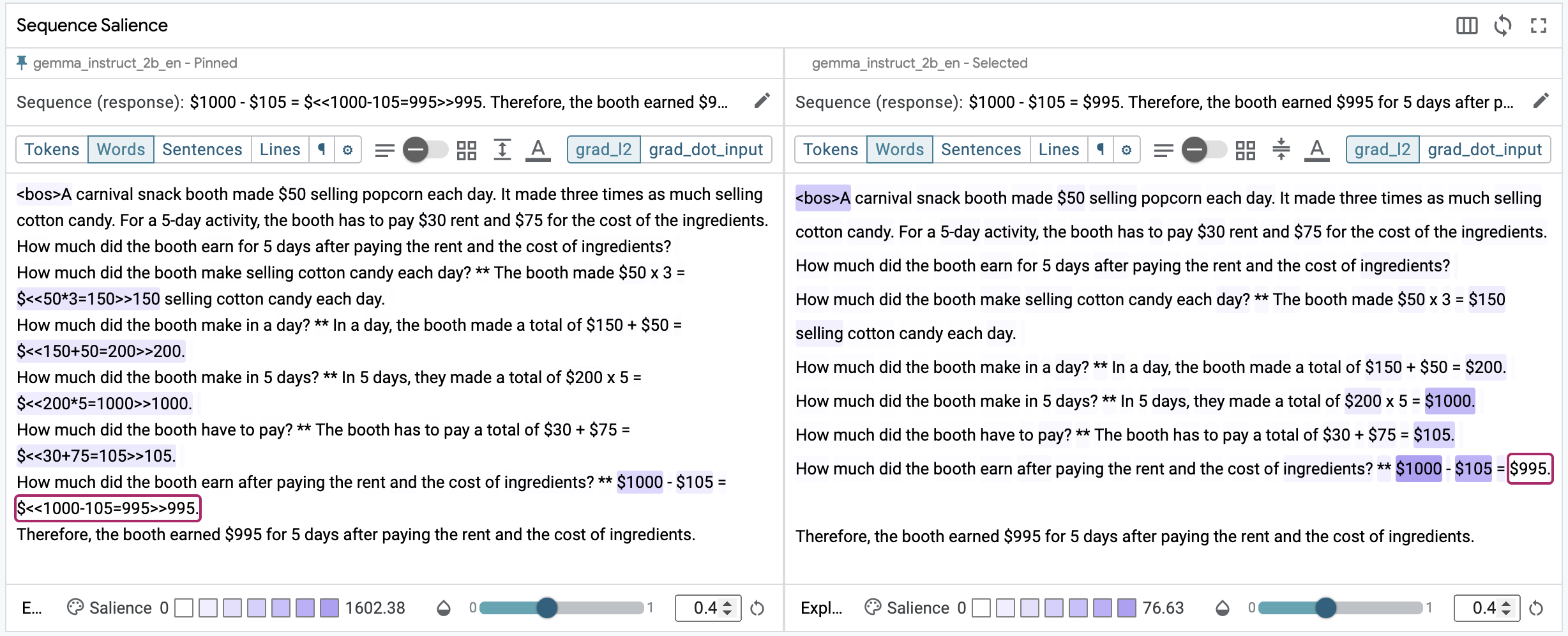
How much did the booth earn after paying the rent and the cost of ingredients? **When we inspect the model's response to a zero-shot prompt in the Sequence Salience module, we notice two things. First, the model failed to compute the correct answer. It was able to correctly set up the problem as the difference between two values, but the calculated value is incorrect ($995 when it should be $895). Second, we see a fairly diffuse heatmap attending near equally to the operands for the final problem and all of the preceding answers to the Socratic questions.
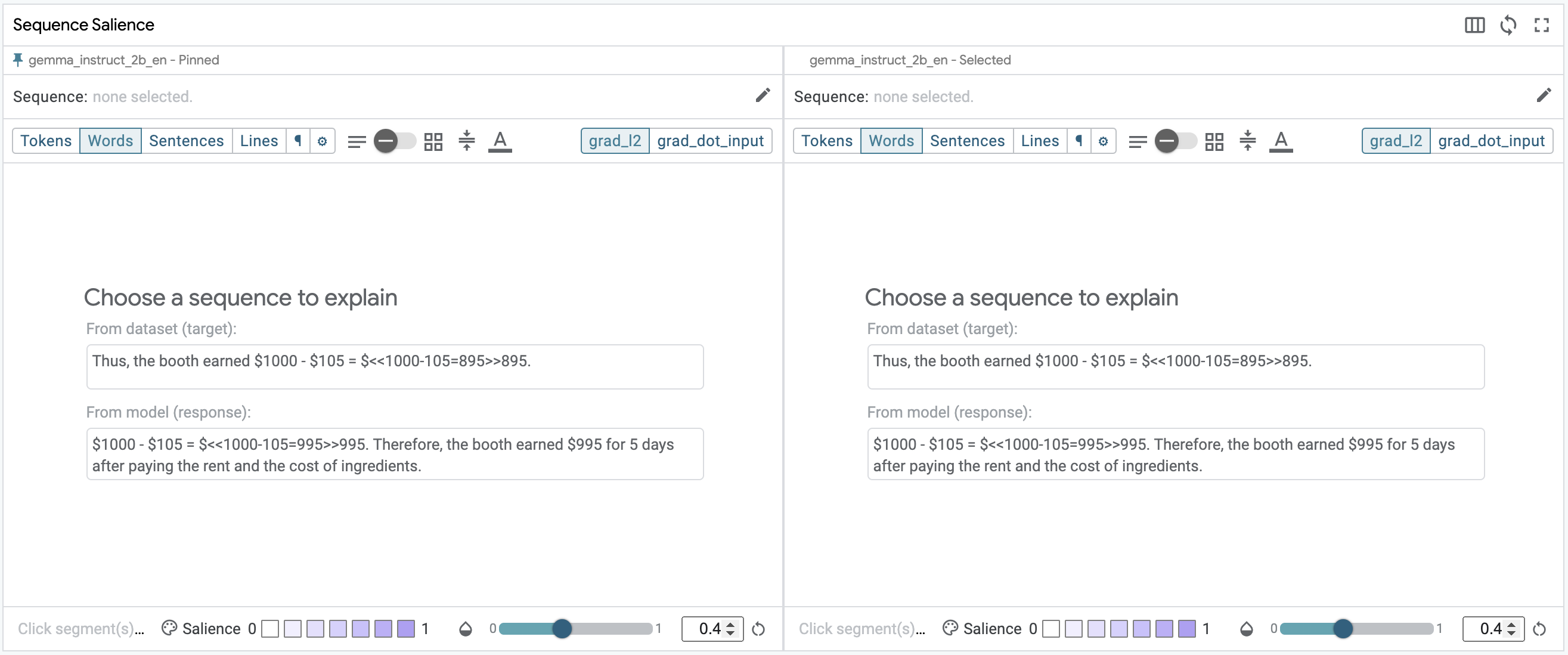
This dataset does provide ground truth, so let's use SxS mode to compare the generated response with the ground truth. The fastest way to enter SxS mode for the selected datapoint is by using the pin button in the main toolbar. When you enable SxS mode, the Sequence Salience module will ask you to choose which target sequence to view on each side. The order doesn't matter, but ground truth is on the left and the models' response is on the right in the figure below.
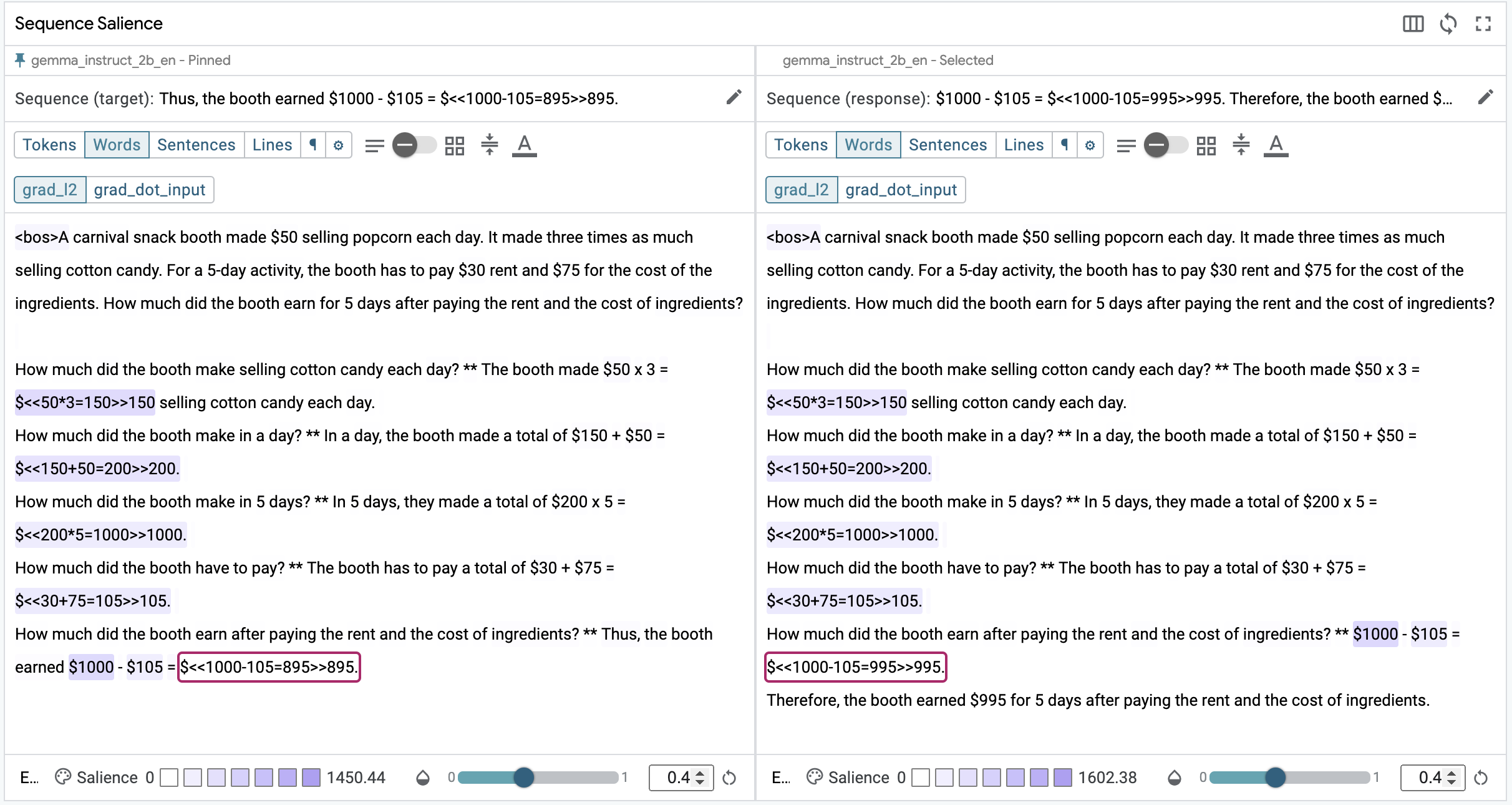
Next, ensure that the same granularity (word-level) is being used on both Sequence Salience visualizations, and then select the segment for the last calculation on both sides. The heatmap is quite similar on both sides; the same diffuse pattern suggesting the model isn't quite sure what to pay attention to.
One possibility that might improve performance is to adjust the prompt so that
the segments used in the calculations are more salient. GSM8K uses a
special calculation annotation to tell the model when it should
employ an external calculator tool during generation. The naive zero-shot prompt
above left these annotations intact and they might be confusing the model. Let's
see what happens when we remove these annotations. Using the
Datapoint Editor we can remove all of the << ... >>
content from the prompt, then use the "Add" button to add it to our dataset, run
generation, and load the example in the Sequence Salience module as the
"selected" datapoint on the right. Choose to view the model's response field in
the Sequence Salience module, ensure the same granularity is being used, and
then select the segment containing the calculated value on both sides, as shown
in the figure below.
We can immediately see that the modified prompt has a much more intense salience map focusing on the operands to the calculation and the preceding answers from which they originate. That said, the model still gets the calculation wrong.
In addition to these between-examples comparisons, LIT's SxS mode also supports comparison between two models. Prior research investigating the necessity of tool use by models has noted that model size does seem to correlate with performance on mathematical reasoning benchmarks. Let's test that hypothesis here.
To enable between-model comparison, first unpin the original example using the button in the main toolbar, then enable the 7B and 2B model instances using the checkboxes (also in the main toolbar). This will duplicate the Sequence Salience module, with the 7B model on the left and the 2B model on the right. Select model response for both, and then select the final calculation result segment to see their respective heatmaps.
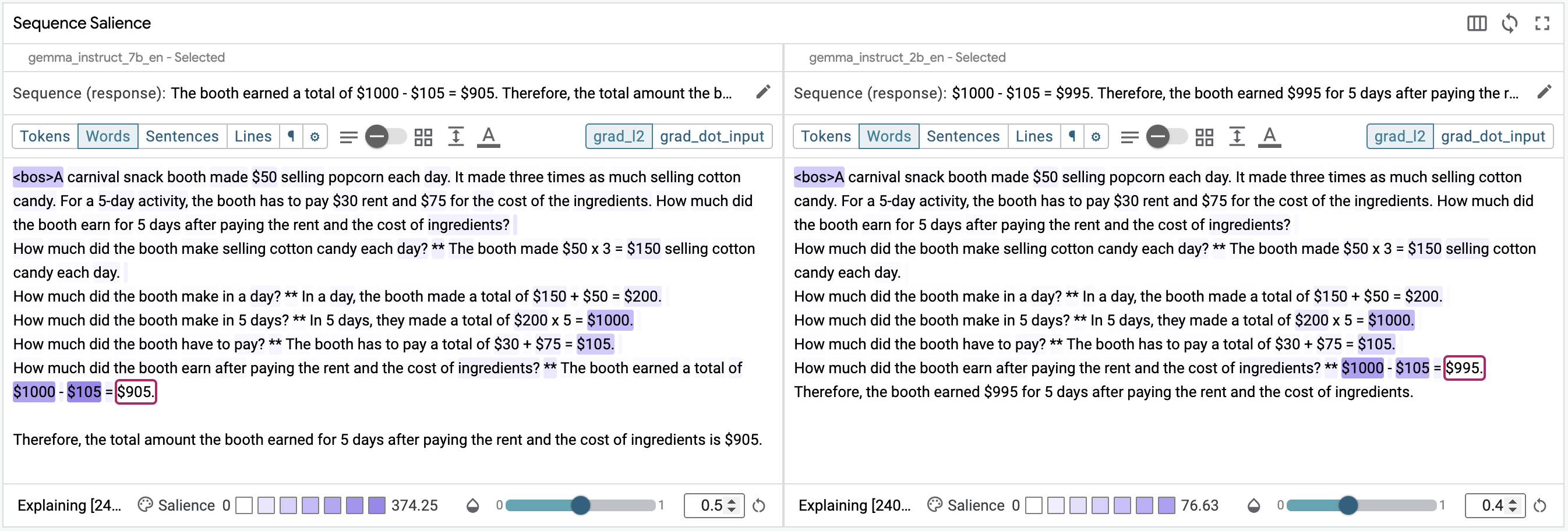
Notice that the heatmaps are quite similar, suggesting the models have similar behavioral characteristics, but that both still get the answer wrong. At this point, it may be possible to improve performance by revisiting different prompting strategies or by training the model to use tools.
Conclusion
The case studies above demonstrate how to use LIT's Sequence Salience module to evaluate prompt designs rapidly and iteratively, in combination with LIT's tools for side-by-side comparison and datapoint editing.
Salience methods for LLMs is an active research area. The LIT team has provided reference implementations for computing gradient-based salience— Grad L2 Norm and Grad · Input—for LLMs in two popular frameworks: KerasNLP and HuggingFace Transformers.
There is considerable opportunity to research how the model analysis foundations described in this tutorial can support richer workflows, particularly as they relate to aggregate analysis of salience results over many examples, and the semi-automated generation of new prompt designs. Consider contributing your ideas, prototypes, and implementations with us via GitHub.
Further Reading
In addition to the links above, the Google Cloud, Responsible AI and Human-Centered Technologies, and the People + AI Research teams have several helpful guides that can help you develop better prompts, including:
- Cloud's overview of prompt design strategies;
- Cloud's best practices for prompt engineering;
- The Responsible Generative AI Tookit;
- The PAIR Guidebook discusses the importance of iterative testing and revision; and
- The interactive saliency explorable dives deep into the inner working of salience methods, and how they can be used.