Frequently Asked Questions¶
Looking for help? Submit bugs, ask questions, suggest content, and request features on our Github issues list.
Model and Data Types¶
LIT can handle a variety of models with different input and output types, and works with any modern ML framework. For more information, see Framework & Model Support.
In addition to text, LIT has good support for different modalities, including images and tabular data. For examples, see:
Tabular demo - multi-class classification on tabular (numeric and categorical string) data, using the Palmer Penguins dataset.
For more details, see the features guide to input and output types.
Languages¶
All strings in LIT are unicode and most components use model-provided tokenization if available, so in most cases non-English languages and non-Latin scripts should work without any modifications.
Scale¶
Dataset Size¶
LIT can comfortably handle 10k-100k datapoints, depending on the speed of the server (for hosting the model) and your local machine (for viewing the UI). When working with large datasets, there are a couple caveats:
LIT expects predictions to be available on the whole dataset when the UI loads. This can take a while if you have a lot of examples or a larger model like BERT. In this case, we recommend adding the flag
--warm_start=1(or passwarm_start=1to theServerconstructor in Python) to pre-compute predictions before starting the server.Datasets containing images may take a while to load. If full “native” resolution is not needed (such as if the model operates on a smaller size anyway, such as 256x256), then you can speed things up by resizing images in your
Datasetloading code.LIT uses WebGL for the embedding projector (via ScatterGL) and for the Scalars and Dive modules (via Megaplot), which may be slow on older machines if you have more than a few thousand points.
If you have more data, you can use Dataset.sample or Dataset.slice to select
a smaller number of examples to load. You can also pass individual examples to
LIT through URL params, or load custom
data files at runtime using the settings (⚙️) menu.
Large Models¶
LIT can work with large or slow models, as long as you can wrap them into the
model API. If you have more than a few preloaded datapoints, however, you’ll
probably want to use warm_start=1 (or pass --warm_start=1 as a flag) to
pre-compute predictions when the server loads, so you don’t have to wait when
you first visit the UI.
Also, beware of memory usage: since LIT keeps the models in memory to support
new queries, only so many models can fit on a single node or GPU. If you want to
load more or larger models than can fit in local memory, you can host your model
with your favorite serving framework and connect to it using a custom
Model class.
We also have experimental support for using LIT as a lightweight model server;
this can be useful, e.g., for comparing an experimental model running locally
against a production model already running in an existing LIT demo. See
remote_model.py
for more details.
Privacy and Security¶
LIT allows users to query the model, as well as to view the loaded evaluation
data. The LIT UI state is ephemeral and exists only in the browser window;
however, model predictions and any newly-generated examples (including as
manually entered in the web UI) are stored in server memory, and if --data_dir
is specified, may be cached to disk.
LIT has the ability to create or edit datapoints in the UI and then save them to
disk. If you do not want the tool to be able to write edited datapoints to disk,
then pass the --demo_mode runtime flag to the LIT server.
I have proprietary data. Is LIT secure for my team to use?¶
We don’t store, collect or share datasets, models or any other information loaded into LIT. When you run a LIT server, anyone with access to the web address of the server will be able to see data from the loaded datasets and interact with the loaded models. If you need to restrict access to a LIT server, then make sure to configure the hosting of your LIT server to do so.
The default LIT development server does not implement any explicit access controls. However, this server is just a thin convenience wrapper, and the underlying WSGI App can be easily exported and used with additional middleware layers or external serving frameworks. See Running LIT in a Docker container for an example.
Workflow and Integrations¶
Sending examples from another tool¶
LIT can read input fields directly from the URL; they should be encoded as
data_<fieldname>=<value>, and field names should match those in the (default)
dataset.
There is also (experimental) support for sending more than one example, as long
as the total URL length is within the browser’s size limit. Specify as above,
but using data0, data1, data2, e.g. data0_<fieldname>=<value>.
Downloading or exporting data¶
Currently, there are three ways to export data from the LIT UI:
In the Data Table, you can copy or download the current view in CSV format - see the UI guide for more details.
In the “Dataset” tab of the settings (⚙️) menu, you can enter a path to save data to. Data is pushed to the server and written by the server backend, so be sure the path is writable.
If using LIT in a Colab or other notebook environment, you can access the current selection from another cell using
widget.ui_state.primary,widget.ui_state.selection, andwidget.ui_state.pinned.
Loading data from the UI¶
There is limited support for this via the settings (⚙️) menu. Select a dataset, and enter a path to load from:
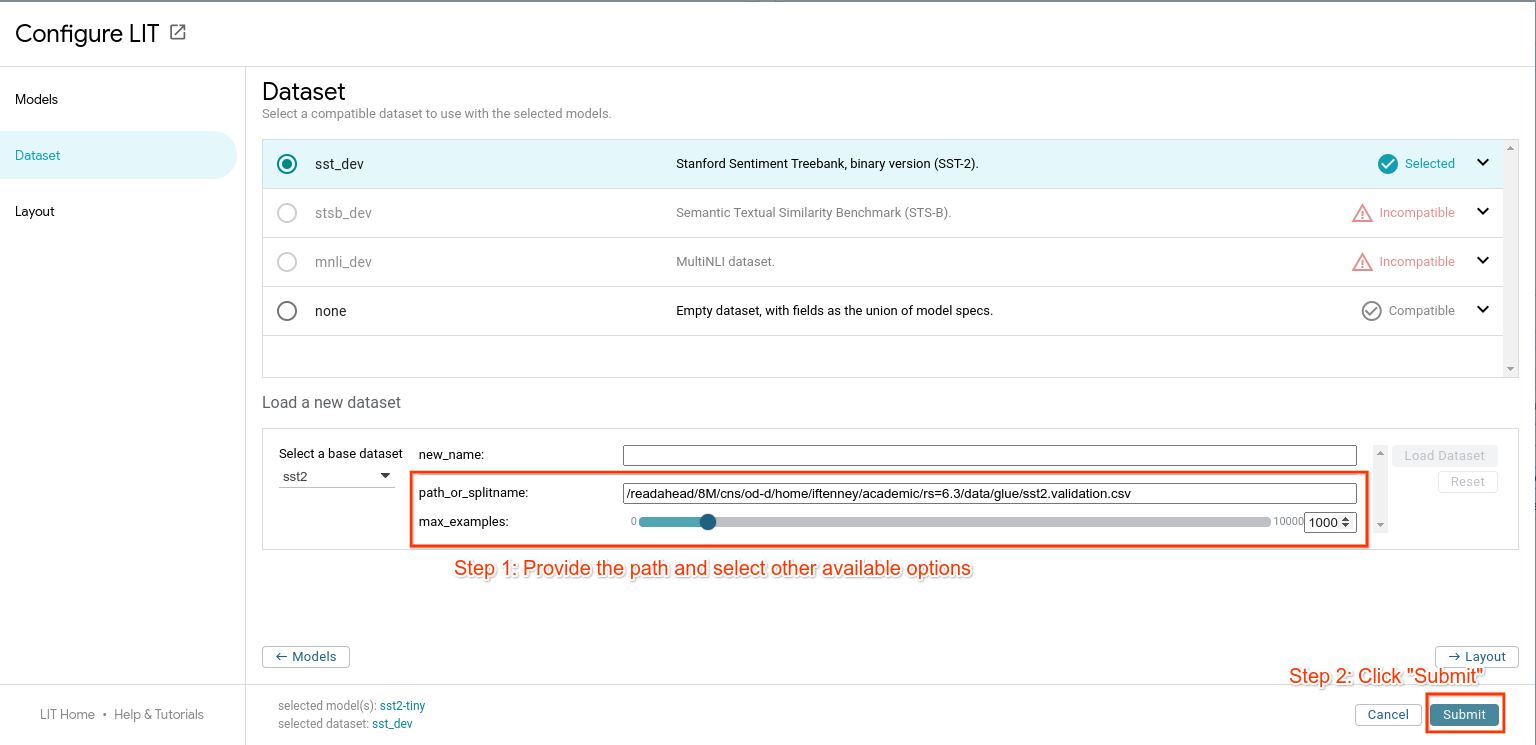
The supported format(s) depend on the dataset class; in most cases, the user
should implement the load() method on their dataset class to handle the
appropriate format.
Using components outside the LIT UI¶
Python components such as models, datasets, and generators are designed to support standalone use. These don’t depend on the LIT serving framework, and you can treat them as any other Python class and use from Colab, regular scripts, bulk inference pipelines, etc. For an example, see the API documentation.
For the frontend, it’s a little more difficult. In order to respond to and
interact with the shared UI state, there’s a lot more “framework” code involved
(see the frontend development guide for more).
We’re working on refactoring the LIT
modules to separate
framework and API code from the visualizations (e.g.
elements), which can
then be re-used in other environments.
Training models with LIT¶
LIT is primarily an evaluation/inference-time tool, so we don’t provide any
official training APIs. However, to facilitate code reuse you can easily add
training methods to your model class. In fact, several of our demos do exactly
this, using LIT’s Dataset objects to manage training data along with standard
training APIs (such as Keras’ model.fit()). See
glue/models.py
for examples.
Debug LIT UI in Colab¶
The LIT instance launched from CLI typically has helpful error messages in the UI. However, this is not the case for the LIT UI in Colab and the error message does not report any stacktrace, which makes debugging very difficult.
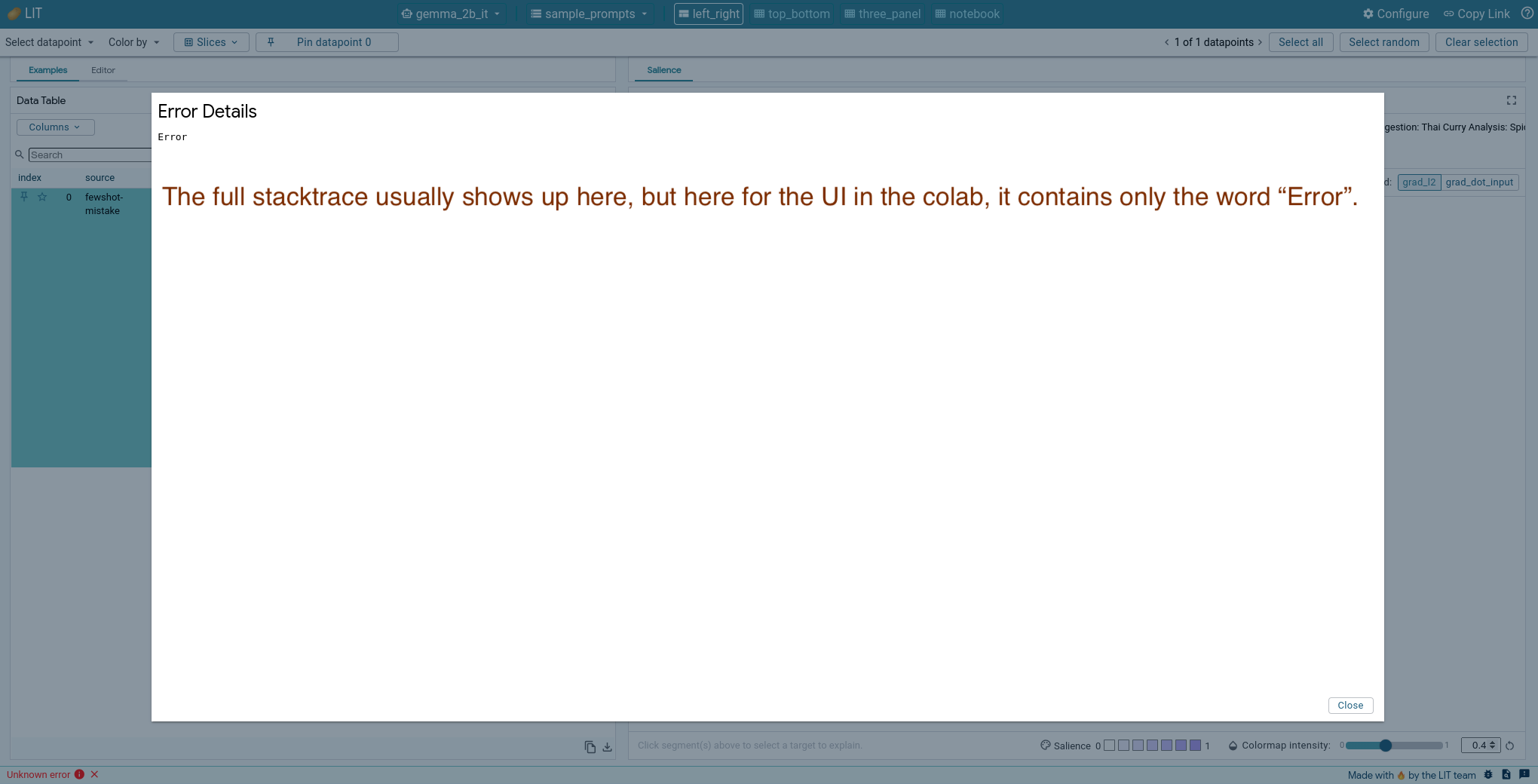
While in Chrome developer tools, you will be able to debug issues solely related to the frontend, but not so for issues related to the backend or on the HTTP request path.
Thus, to show the full stacktrace, you would need to find the HTTP request sent from the frontend to the backend, compose the same request in colab and send it to the server.
When rendering the UI, display it in a separate tab to make things a bit easier to work with, e.g.
lit_widget.render(open_in_new_tab=True).Open Chrome developer tools, go to “Sources” tab and find the file client/services/api_service.ts and set a breakpoint right after where the HTTP request is set up in the
queryServermethod, e.g. after this lineconst res = await fetch(url, {method: 'POST', body});.Note it is possible that the whole frontend source code is compiled into a
main.jsfile, and the code is not exactly the same as that in LIT frontend source code. You might have to do a bit digging to find the right line.
Go to the UI and trigger the behavior that causes the error. Now in Chrome developer tools you will be able to see the variables and their values in the
queryServermethod. Copy the values of theurlandbodyvariables in the method.Go back to Colab, compose your HTTP request method. Look for the main server address printed out from
lit_widget.render(open_in_new_tab=True).

Let’s say the server address is “https://localhost:32943/?” as shown above, the
body variable obtained earlier has value “request_body_text” and the url
variable has value “./get_preds?param1=value1”. Then your HTTP request will be
like this:
! curl -H "Content-Type: application/json" \
-d "request_body_text" \
-X POST "http://localhost:32943/get_preds?param1=value1"
Run this in Colab and you should be able to retrieve the full stacktrace of the error.