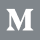Exploring a Sentiment Classifier
Or, run your own with examples/glue/demo.py
How well does a sentiment classifier handle negation? We can use LIT to interactively ask this question and get answers. We loaded up LIT the development set of the Stanford Sentiment Treebank (SST), which contains sentences from movie reviews that have been human-labeled as having a negative sentiment (0), or a positive sentiment (1). For a model, we are using a BERT-based binary classifier that has been trained to classify sentiment.
Using the search function in LIT’s data table, we find the 67 datapoints containing the word “not”. By selecting these datapoints and looking at the Metrics Table, we find that our BERT model gets 91% of these correct, which is slightly higher than the accuracy across the entire dataset.
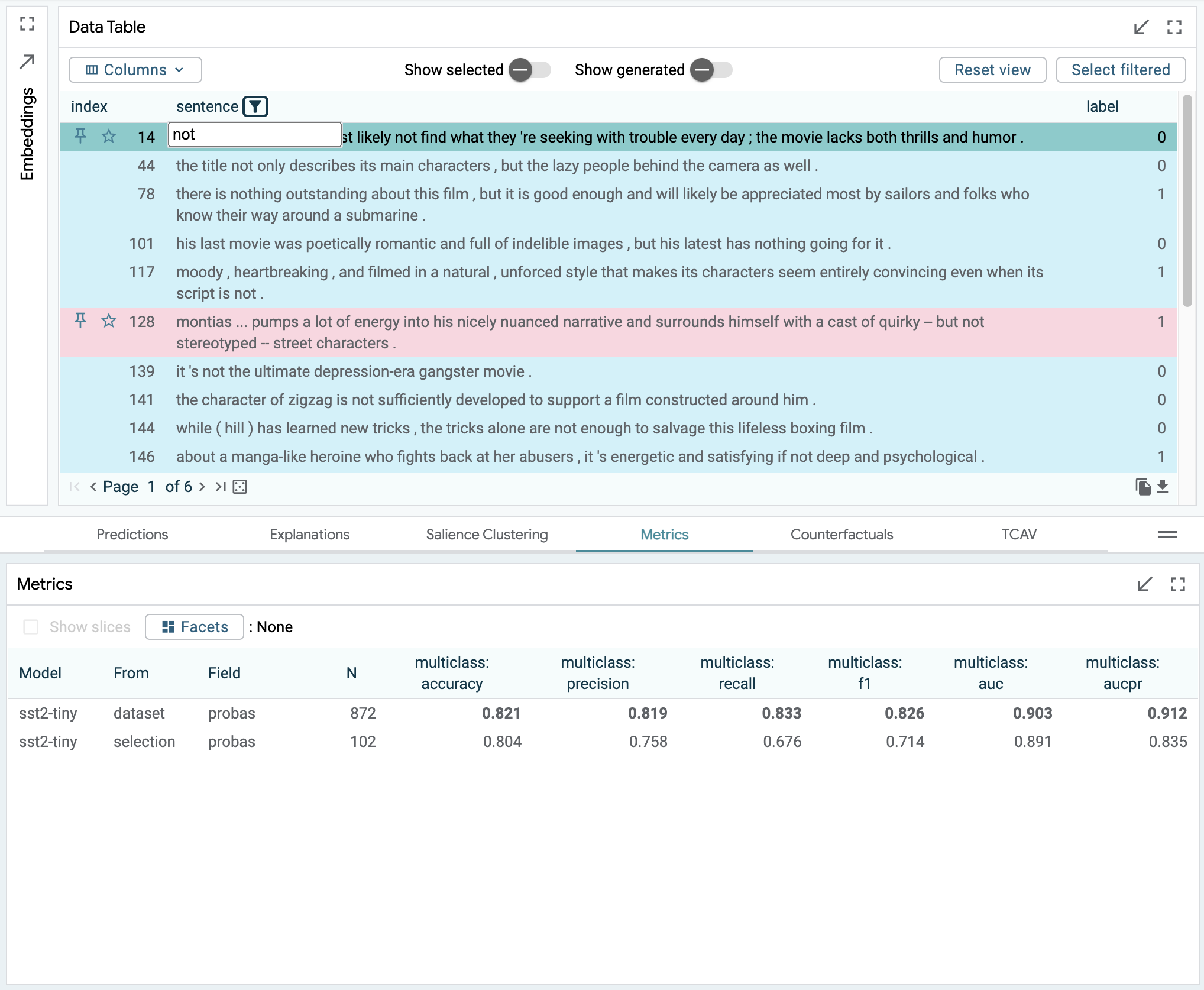
But we might want to know if this is truly robust. We can select individual datapoints and look for explanations. For example, take the negative review, “It’s not the ultimate depression-era gangster movie.”. As shown below, salience maps suggest that “not” and “ultimate” are important to the prediction. We can verify this by creating modified inputs, using LIT’s datapoint editor. Removing “not” gets a strongly positive prediction from “It’s the ultimate depression-era gangster movie.”.
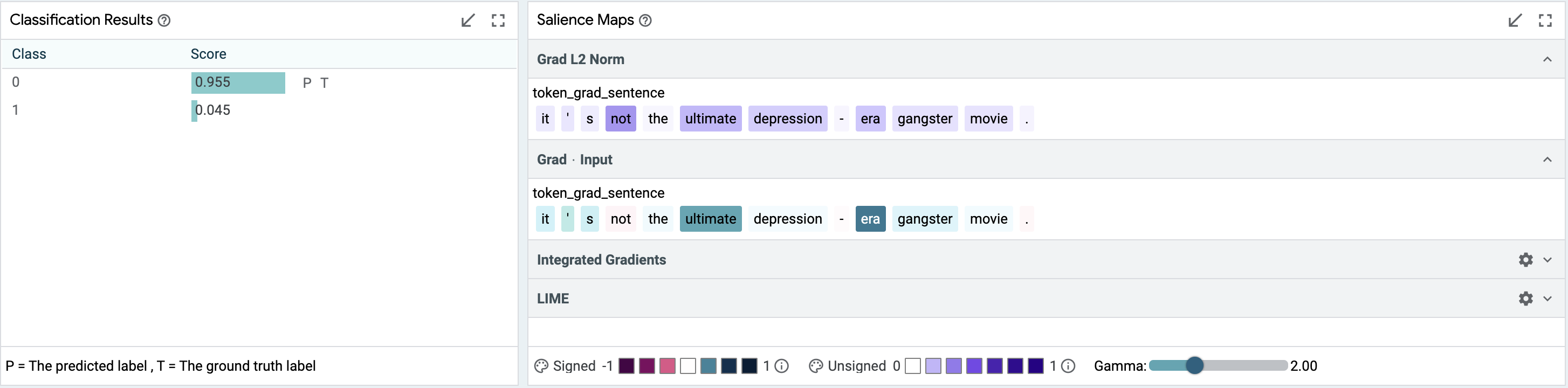
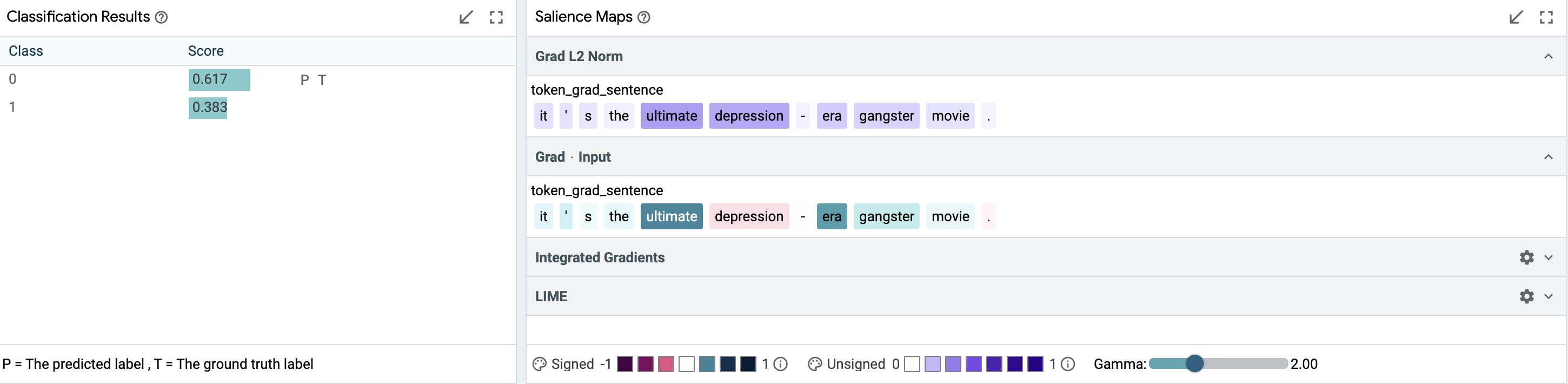
Using the LIT features of data table searching, the metrics table, salience maps, and manual editing, we’re able to show both in aggregate and in a specific instance, that our model handles negation correctly.