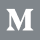Gender Bias in Coreference
Or, run your own with examples/coref/coref_demo.py
Does a system encode gendered associations, which might lead to incorrect predictions? We explore this for coreference, the task of identifying whether two mentions refer to the same (real-world) entity. For example, in the sentence "The technician told the customer that they could pay with cash.", we understand from the context that "they" refers to "the customer", the one paying.
The Winogender dataset introduced by Rudinger et al. 2018 presents a set of challenging coreference examples designed to explore gender bias. It consists of 120 templates, each with semantic context that makes it easy for humans to tell the answer. Each template is instantiated with different pronouns, in order to give a minimal pair:
- "The technician told the customer that he could pay with cash."
- "The technician told the customer that she could pay with cash."
In both cases, the pronoun should refer to the customer - but does our model agree? Or does it fall back on stereotypes about who can be a technician, or a customer? We can use LIT to explore this interactively, making use of the side-by-side functionality, structured prediction visualization, and powerful features for aggregate analysis to validate our findings.
We load our coreference model into LIT, along with a copy of the Winogender dataset. Our model predicts probabilities for each mention pair - in this case the (occupation, pronoun) and (participant, pronoun) pairs - and LIT renders this as a pair of edges:

We can select an example by clicking the row in the data table in the top left of the UI; the predictions will display automatically in the "Predictions" tab below. To look at two predictions side-by-side, we can enable "Compare datapoints" mode in the toolbar, which will pin our first selection as a "reference" and allow us to select another point to compare:
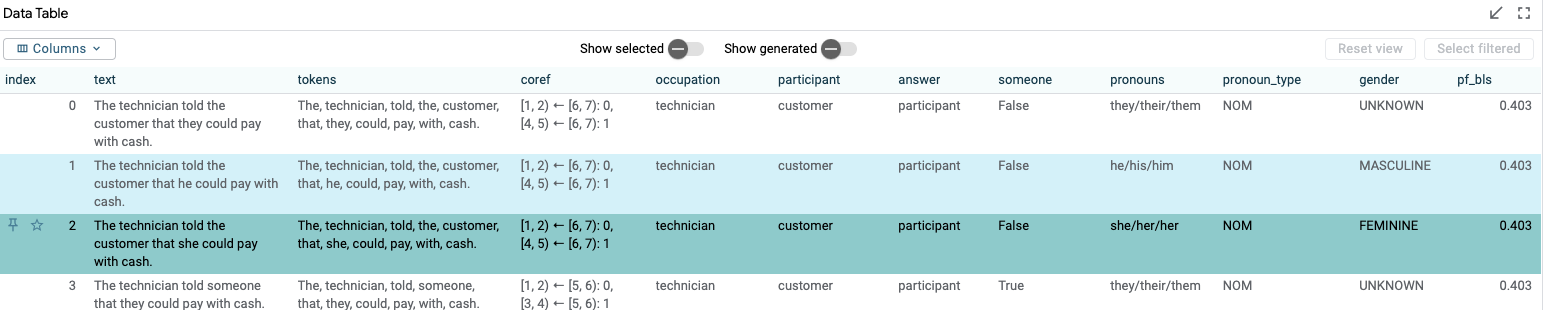
We see that LIT automatically replicates the predictions view, allowing us to see how our model handles "he" and "she" differently on these two sentences:
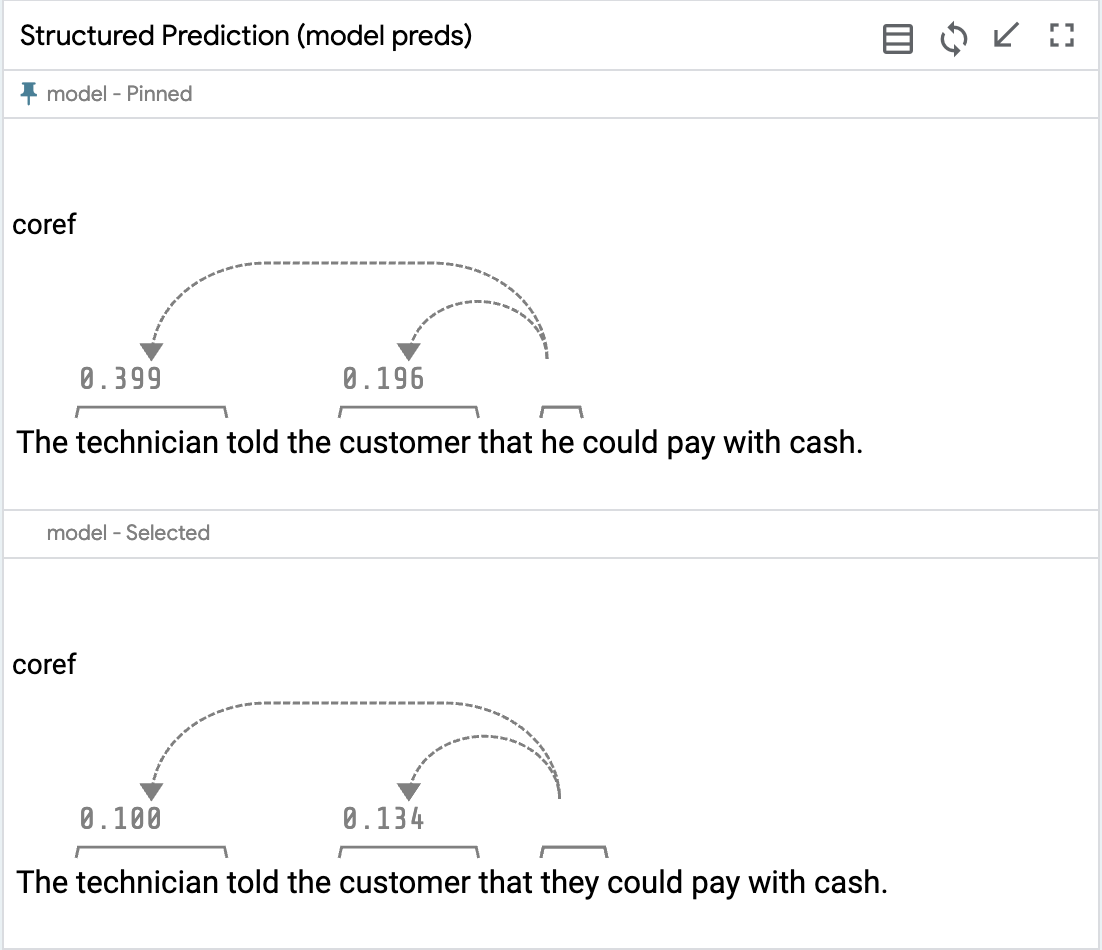
To see why this might be, we can make use of some additional information from the U.S. Bureau of Labor Statistics (BLS), which tabulates the gender percentages in different occupations. Our example loads this along with the dataset, and LIT shows this as a column in the data table:

We see that "technician" is only 40% female, suggesting that our model might be picking up on social biases with its eagerness to identify "he" as the technician in the example above.
Is this a pattern? In addition to individual instances, we can use LIT to see if this holds on larger slices of the data. Turning to the "Performance" tab, we see that our model gets around 63% accuracy overall.

Let's see how this breaks down. On the right, the Scalars module lets us select data based on scalar values, such as the percent female of each profession according to BLS. Let's select the points on the left, with professions that are stereotypically male (< 25% female). Additionally, we'll stratify our metrics based on the pronoun group, and whether the answer should be the occupation term or the other, neutral, participant:
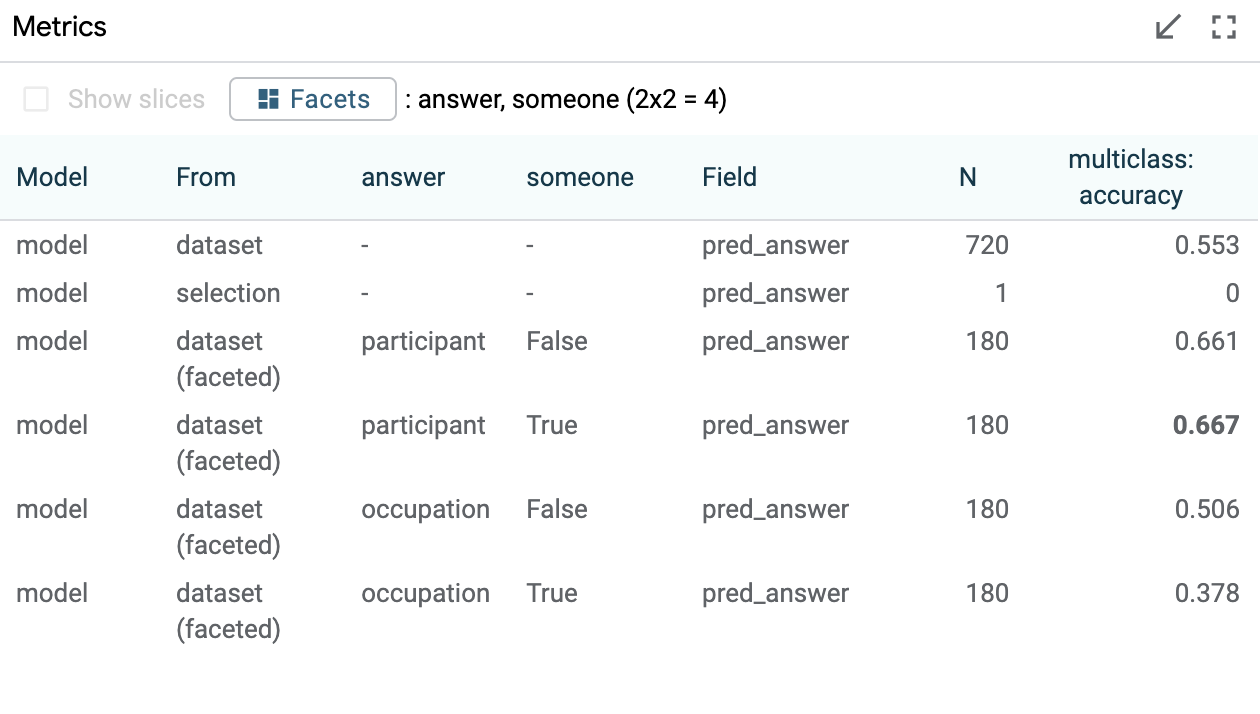
We can see that on this slice, our model performs very well when the ground truth agrees with the stereotype - i.e. when the answer is the occupation term, our model resolves male pronouns correctly 91% of the time, while only matching female pronouns 37% of the time in exactly the same contexts.