Adding Non-Input Features To Perform Subgroup Analysis
When loading a pre-trained model and accompanying dataset into the What-If Tool, typically one would think that every feature included in the dataset has to be used by the pre-trained model to generate predictions. However, not all features included in a dataset must behave as input to the model. Sometimes these non-input features (features that are present in a dataset, but are not used in model prediction) are utilized for evaluation purposes, behaving instead as a means of slicing the dataset into subgroups to conduct deeper analysis.
The What-If Tool is actually capable of displaying additional features in datapoints that are not used to query the trained model. Since the What-If Tool requires either a protocol message (tf.Example or SequenceExample), or data expressed as JSON lists or dicts to read files efficiently, there should be no issues adding non-input features—so long as the dataset has the required input feature(s) for the pretrained model to recognize when the What-If Tool queries for predictions.
- For example, if the pre-trained model expects an image file as input, but the dataset included for evaluation purposes also contains non-image features (such as categories and other attributes that describe aspects about the image), then just make sure all the input features are formatted correctly. That way, the pre-trained model will not ingest the wrong input feature or return an error because it was not expecting additional non-input features.
- Also, for each non-input feature column added to the dataset, ensure that it is the same length as the number of datapoints available in the dataset. Mismatch in dimensions could result in loading errors.
Once added, as with any other feature, the non-input features are available to analyze across all workspaces: Datapoint Editor, Performance & Fairness, and Features Overview.
The example in this tutorial borrows from the Smile Detector Demo. There, the task was to predict whether a person in a photo is smiling or not. Trained using only image data, the dataset also contains many feature attributes that describe certain aspects about the person in the photo. For example, is the person in the photo wearing a hat? Did they have make-up on? Did they have a beard?
It's worth acknowledging that all of the attribute annotations (which is captured as our non-input features in this tutorial) in CelebA come operationalized as binary categories.
For example, the Young attribute, which loosely and presumably represents perceived behavior or appearance of young people, is denoted as either present or absent in the image. In other words, the absence of Young in an image does not always imply that the image features an Old celebrity.
Warning: CelebA's categorizations do not reflect real human diversity of attributes. In this demo, we’re dubbing the Young attribute as age group, where the presence of the Young attribute in an image is labeled as a member of the young age group and the absence of the Young attribute is labeled as a member of the old age group. We’re also treating the Male attribute as gender, where the presence of the Male attribute in an image is regarded the same, but the absence of the Male attribute (Not Male in CelebA) is regarded as Female in our demo.
Basically, we’re making assumptions about the information in the dataset that is not mentioned in its original paper. As such, results in this demo is tied to the ways the attributes have been operationalized and annotated by the authors of CelebA.
This model should not be used for commercial purposes as that would violate CelebA's non-commercial research agreement.
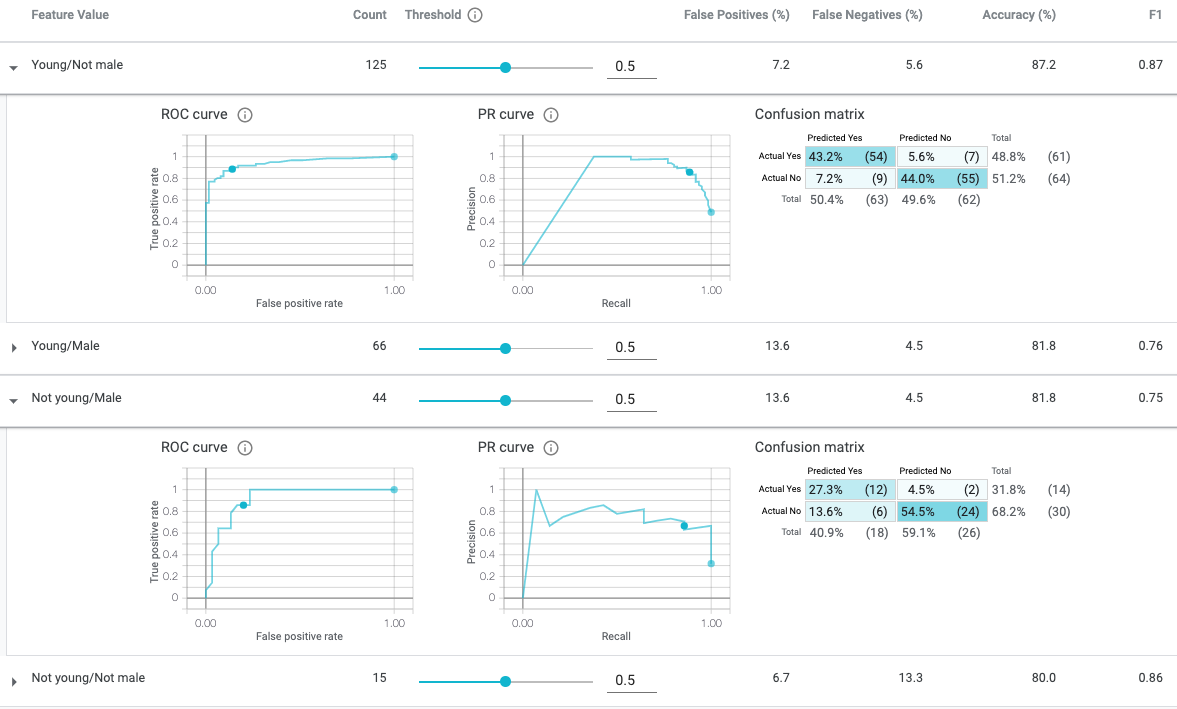
As mentioned earlier, one of the advantages to including non-input features is the ability to evaluate model performance with respect to subgroups. This can be done by selecting the feature using Slice By in the Configure module located in the Performance & Fairness workspace as shown below:

Among the list of feature attributes were categories associated with age group and perceived gender—feature attributes that may be regarded as sensitive subgroups to evaluate performance across to ensure fairer, more desirable outcomes. As shown in the figure above, both of those features (age and gender) can be selected for analysis in the Configure module by selecting one of those features (say, age) using the Slice By drop down and selecting the second feature (say, gender) using the Slice By (secondary) drop down.
Using a combination of features that represent individual characteristics to explore the impact of model results with respect to these combinations is known as intersectional model analysis. Intersectionality explores how an individual’s identity and experiences (as captured in input features in the dataset) are shaped not just by unitary characteristics, but instead by a complex combination of many factors. The following is an example of what intersectional model analysis looks like in the What-If Tool:
The What-If Tool was created to help you mitigate, or leverage, the learned signal of a characteristic feature pertaining to a subgroup. As you work with different variables and define tasks for them, it can be useful to think about what comes next.
For example, where are the places or contexts where the interaction of the characteristic feature and the task could be a concern?
With the What-If Tool, anyone can transform their analysis to evaluate model performance across subgroups rather than in aggregate. The ability to use non-input features as a way to perform such analysis provides flexibility for practitioners that wish to omit such features in training, but utilize later for evaluation.