Debugging a Text Generator
Or, run your own with examples/t5_demo.py
Does the training data explain a particular error in text generation? We can use LIT to analyze a T5 model on the CNN-DM summarization task. LIT’s scalar plot module allows us to look at per-example ROUGE scores, and quickly select an example with middling performance.
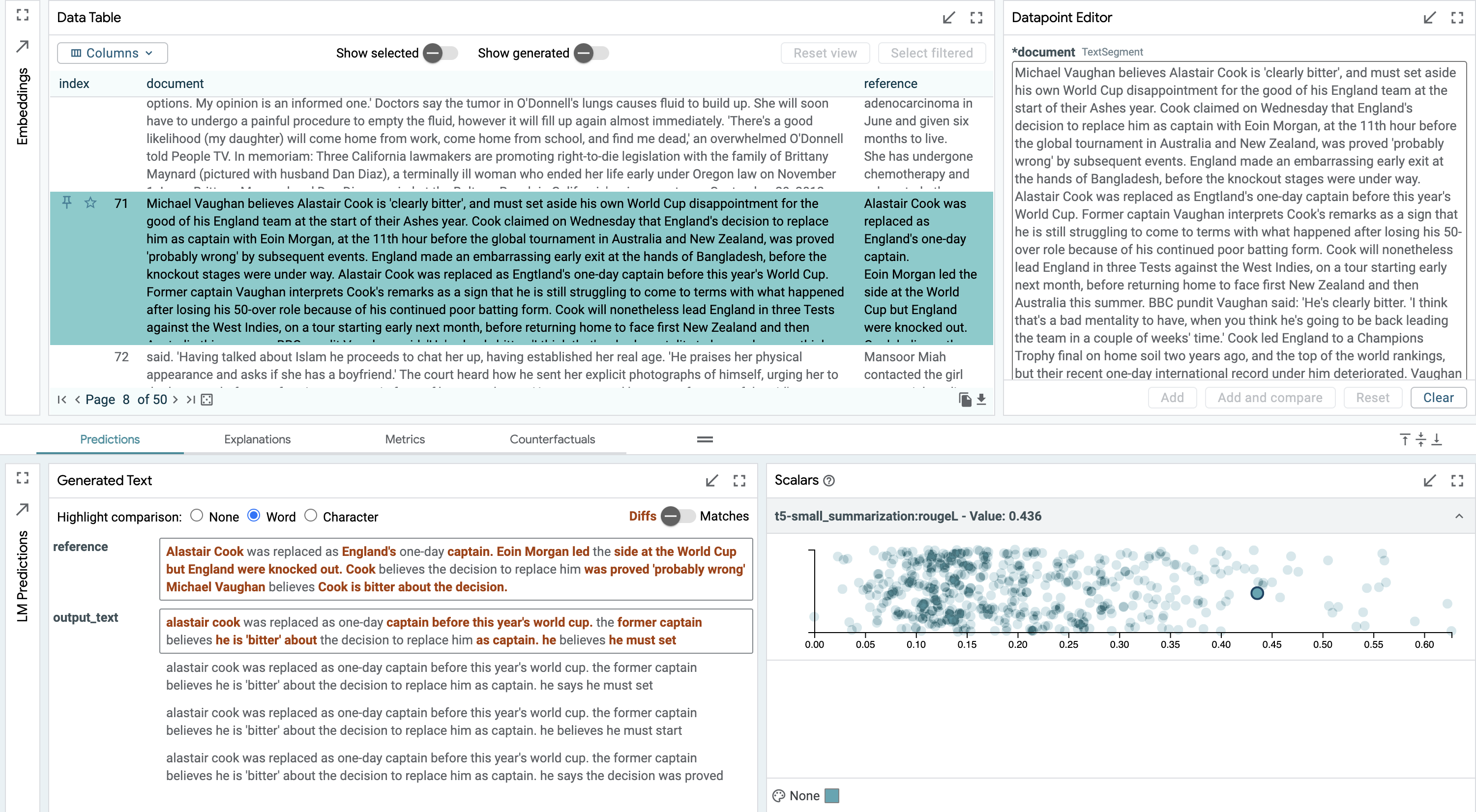
We find the generated text contains an erroneous subject: "[A]lastair [C]ook was replaced as captain by former captain ...". In reading the input text, we can see that he was replaced as captain by Eoin Morgan, and not by a former captain. Another former captain does have a quote in the input text, and the model seemed to confuse these two subjects when generating its summary.
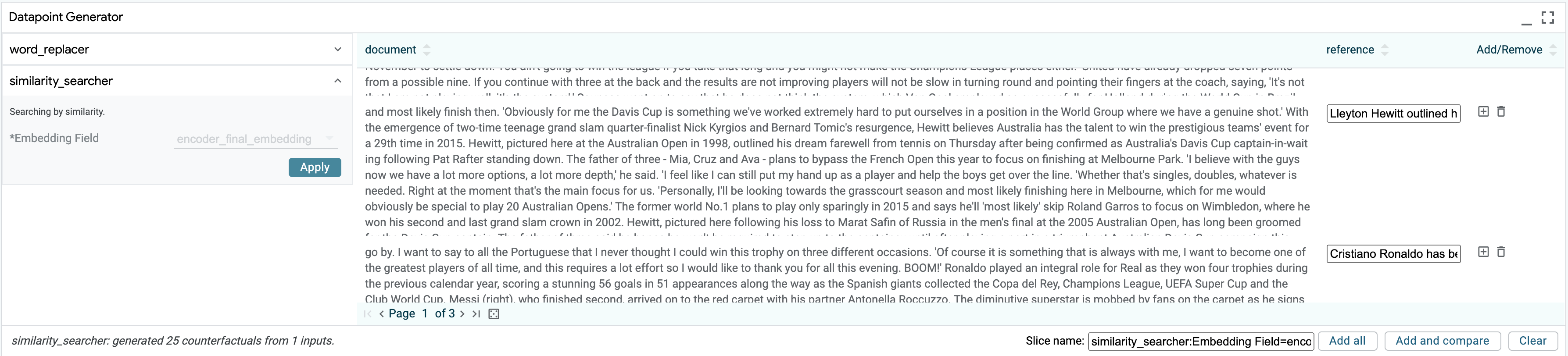
To investigate how T5 arrived at this prediction, we utilize the “similarity searcher” component through the counterfactual generator tab. This performs a fast approximate nearest-neighbor lookup from a pre-built index over the training corpus, using embeddings from the T5 decoder. With one click, we retrieve the 25 nearest neighbors to our datapoint of interest from the training set and add them to the LIT UI for inspection. We can see through the search capability in the data table that the words “captain” and “former” appear 34 and 16 times in these examples–along with 3 occurrences of “replaced by” and two occurrences of “by former”. This suggests a strong prior toward our erroneous phrase from the training data most related to our datapoint of interest.